
Extending go test for LLM Evaluation
Testing LLM-powered systems presents new challenges. Unlike traditional software, where we can assert exact outputs, LLMs produce intentionally non-deterministic outputs that are difficult to assert with standard testing libraries. For the Mattermost Agents plugin, we faced this challenge. In the spirit of keeping it simple, we opted to extend Go’s existing testing framework rather than reinvent the wheel or use a large third-party system.
LLM as a Judge
Traditional unit tests work great when you can predict exact outputs:
func TestAdd(t *testing.T) {
result := add(2, 2)
assert.Equal(t, 4, result)
}But how do you test an AI that summarizes conversations? Each run might produce slightly different wording while conveying the same meaning. You can’t simply assert string equality.
One solution is to use another LLM call to evaluate outputs based on semantic criteria rather than exact matches. The output text is judged against a “rubric” of text evaluations, and the LLM decides if the test passes or fails. In the plugin, we have rubrics like “contains the usernames involved as @mentions if referenced” and “mentions positive feedback to react scan” to determine if the LLM is responding in the way we want it to.
Eval Tests Extending Rather Than Replacing
To keep things simple, we built on Go’s testing framework instead of creating something new. Here’s the core structure:
type EvalT struct {
*testing.T
*Eval
}
func Run(t *testing.T, name string, f func(e *EvalT)) {
numEvals := NumEvalsOrSkip(t)
eval, err := NewEval()
require.NoError(t, err)
e := &EvalT{T: t, Eval: eval}
t.Run(name, func(t *testing.T) {
e.T = t
for i := range numEvals {
e.runNumber = i
f(e)
}
})
}The EvalT type embeds testing.T, giving us all the familiar testing methods while adding evaluation-specific functionality. This composition approach means:
- Existing tooling usually works fine
- Developers already know how to write and run these tests
- CI/CD pipelines need minimal changes
- Test discovery and filtering work out of the box
We don’t want to run the evaluations all the time, right now the easiest way add parameters like this to go tests is environment variables. This keeps evaluations opt-in. Regular go test runs skip expensive LLM calls, while GOEVALS=1 go test runs the full evaluation suite.
We define a way to use all of this to run LLM Rubrics:
func LLMRubricT(e *EvalT, rubric, output string)Which means we can write tests that feel like regular go tests:
func TestEval(t *testing.T) {
tests := []struct {
name string
input string
rubric string
}{
{
name: "cat message",
message: "I just love cats! They are so cute!",
rubric: "is positive about cats",
},
}
for _, tc := range tests {
evals.Run(t, tc.name, func(t *evals.EvalT) {
result, err := doLLMPoweredThing(t.LLM, input)
require.NoError(t, err)
assert.NotEmpty(t, result)
evals.LLMRubricT(t, tc.rubric, result)
})
}
}
With this, it all feels like a regular go test. We can even mix in regular assertions like we normally would.
Real-World Data Testing: Working with Production Conversations
Synthetic tests only get you so far. We wanted to test on actual Mattermost conversations with all their real-world complexity.
After implementing a helper for loading thread data tests end up looking something like:
func TestProcessConversation(t *testing.T) {
evalConfigs := []struct {
filename string
rubrics []string
}{
{
filename: "test_conversation.json",
rubrics: []string{
"mentions that @user1 said they will be ready",
// ...
},
},
}
for _, config := range evalConfigs {
evals.Run(t, config.filename, func(t *evals.EvalT) {
threadData := evals.LoadThreadFromJSON(t, config.filename)
// ... process conversation ...
for _, rubric := range config.rubrics {
evals.LLMRubricT(t, rubric, response)
}
})
}
}Developer Experience: The Interactive TUI Viewer
Test results need to be actionable. Given how easy it is these days to write developer tools, we built a viewer using the Bubble Tea framework that makes evaluation results easier to use.
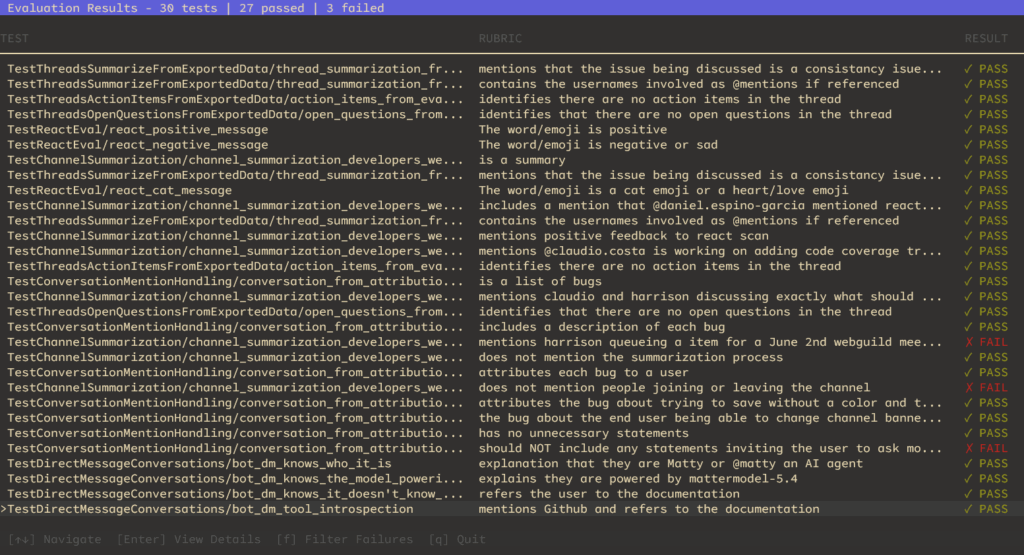
The viewer lets you easily see all the data about the test results so that you can iterate on prompts quickly. It also supports running the tests directly, so you don’t have to remember to set environment variables.
# Run evaluations and immediately view results
evalviewer run -v ./conversations
# View existing results
evalviewer view -file evals.jsonlFuture Evolution: Structured Test Output with future Go versions
Currently, we write evaluation results to a separate JSONL file. There is a PR merged currently slated for go 1.25 that introduces the Attr method for structured test metadata. This will let us embed evaluation results directly in test output:
// Current implementation
func RecordScore(e *EvalT, result *EvalResult) {
log := EvalLogLine{
// ...
Rubric: result.Rubric,
Score: result.Score,
Reasoning: result.Reasoning,
Pass: result.Pass,
}
f, err := os.OpenFile("evals.jsonl", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
// ... write json to file ...
}
// Future implementation
func RecordScore(e *EvalT, result *EvalResult) {
e.T.Attr("eval_rubric", result.Rubric)
e.T.Attr("eval_score", result.Score)
e.T.Attr("eval_reasoning", result.Reasoning)
e.T.Attr("eval_pass", result.Pass)
}With the new Attr feature, we can use the regular structured output of the go test command instead of having a separate results file. This will simplify handling the results and enable better compatibility with other tooling, like the evalviewer we created, standard Go, and third-party tools. It will enable us to do things the Go way.
All the code is open source as part of Mattermost Agents. Feel free to explore the code, give feedback, and adapt the patterns for your own AI testing needs.




