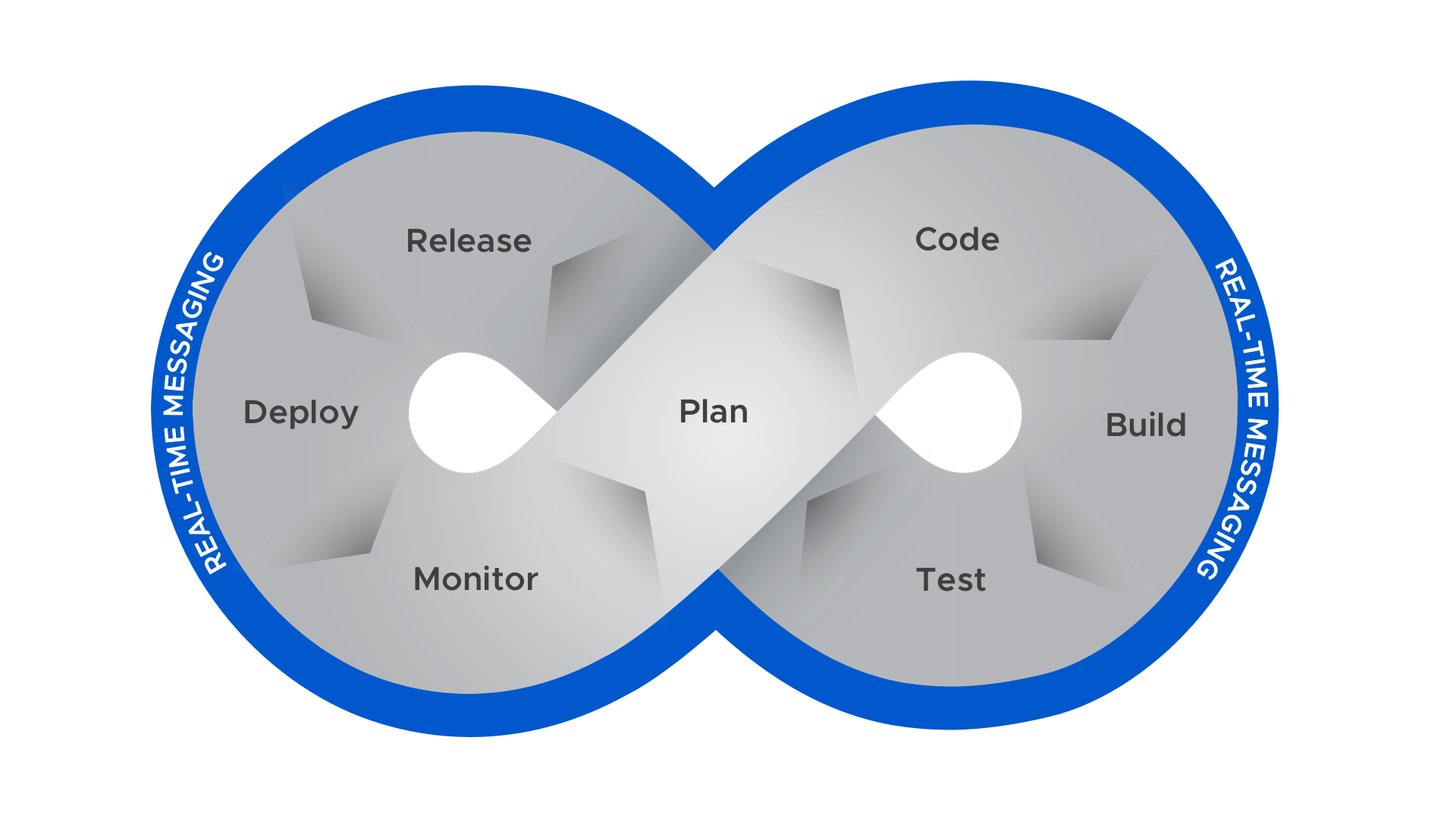
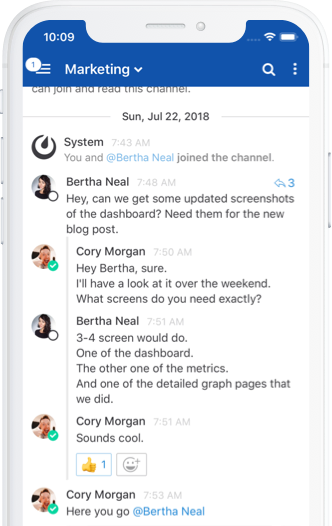
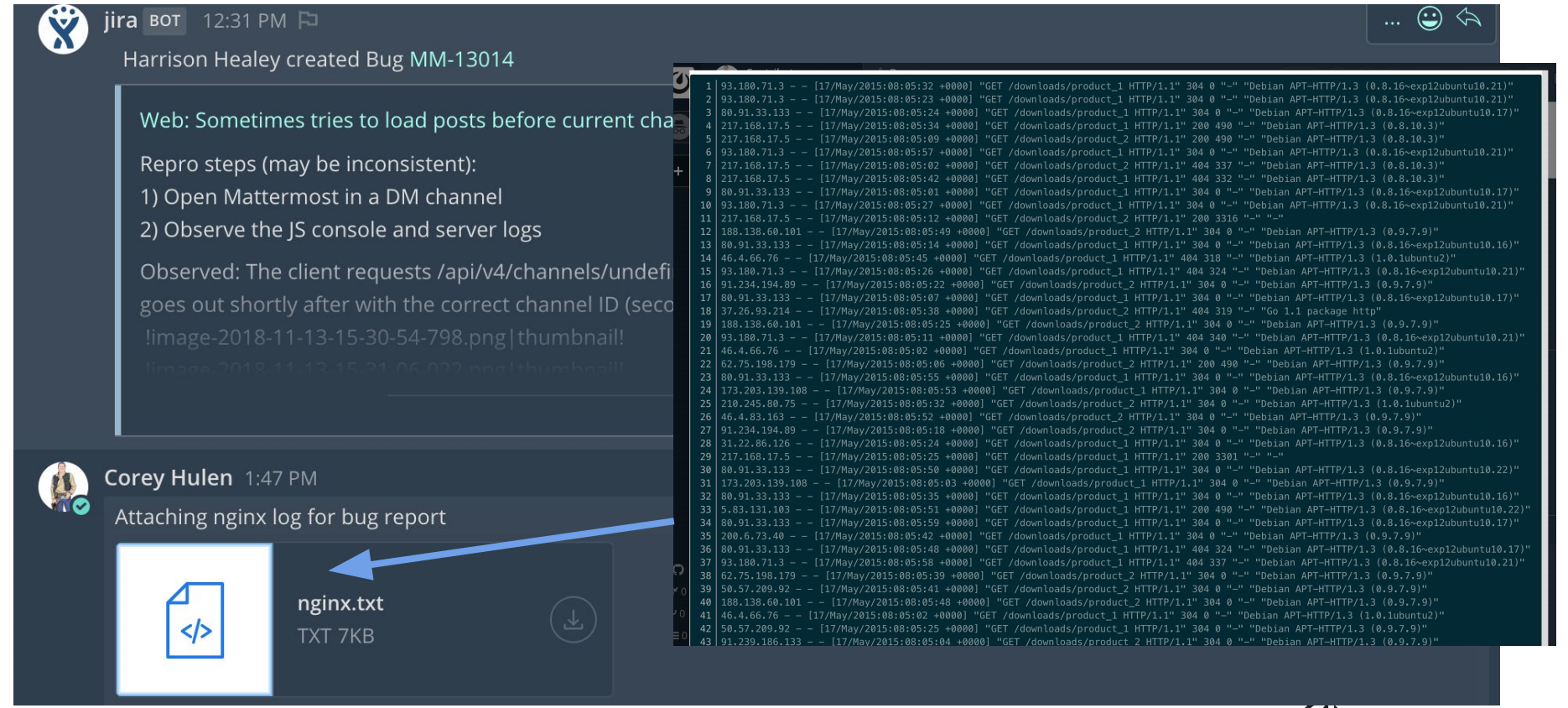
The Keys to DevOps Success
Organizations choose DevOps tools and practices based on two factors: the best available information and their internal culture. Long-term DevOps success is based on using tools that facilitate an ample amount of good information and nurturing a change-positive, trusting environment. With both these factors in place, better decisions get made throughout the DevOps lifecycle.
About this document
We surveyed and interviewed dozens of users of Mattermost and other messaging applications. We spoke to experts throughout the technical world to see how DevOps was changing, and the various ways ChatOps was influencing organizations to think about their end-to-end DevOps lifecycle. Finally, we researched how users were taking advantage of ChatOps at each phase, from planning to retrospective.
Been there, done that. Five times, in fact!
Information is more than just logs. It includes awareness of best practices, understanding of engineering goals and organizational strategy, and an accurate assessment of both team skills and any particular tool’s abilities. For example, it’s easy to imagine how implementing a microservice-based infrastructure would have a higher chance of success if a team has built a similar one before. DevOps is largely driven by the ability to replicate models and processes, or conversely, abandon existing processes based on steadily improving information.
Because information is consumed by DevOps teams at multiple strata: operational, tactical, or strategic, data sources must include an equally wide range, from log files, to internal team feedback, to consumer response (that’s money, honey). Consistently improving the quantity and availability of good information is vital.
DevOps success is a long game: while there may be cases of massive overnight switchovers, DevOps processes are usually a series of small and steady decisions, based on the best information at hand.
Top 4 Reasons for Developer Messaging
- Facilitate collaboration
- Automate manual work
- Unify disparate tools
- Democratize information
Culture needs air to breathe. Not hot air, just air
Culture is an equally important part of a long-term DevOps success strategy. A few aspects that are particularly relevant to those in DevOps are:
- How does your organization view change?
- How does it foster productive conversation?
- How does it handle conflict or criticism?
- How does it make decisions?
- Is there trust in decisions made across the organization?
Making DevOps strategy a reality requires a culture that embraces change, while safeguarding stability. Being able to understand this balance is a shared responsibility, and failing to achieve the balance is a common cause of chaos. When stability-loving customers, and the sales teams who love them, are adversely affected by technical teams who are eager for change, but unwilling to protect performance and uptime, it becomes a tug-of-war that can destroy an organization from within. A team that can discuss these differing viewpoints and arrive at a consensus is best suited to make mature decisions around tools and process.
Trust (…) is our willingness to be vulnerable to the actions of others because we believe they have good intentions and will behave well toward us.
Sandra J. Sucher and Shalene Gupta,
The Trust Crisis, July 2019, Harvard Business Review
Having the ability to make mistakes and change direction along the way is a key aspect of DevOps-friendly culture. Automation, testing, continuous delivery, and other principles lead to overall quality, user experience, and developer happiness, which creates a positive feedback loop of growing trust.
The other important aspect of culture is alignment. Organizations spend millions to ensure executive teams are explaining and sharing their vision with clarity. HR and Engineering managers spend hours building onboarding and training programs to teach staff how to use the company’s mission and fundamental values to make decisions. The goal is alignment across all teams. This means less silos, faster flow of information, and quicker resolution to challenges.
“The stronger alignment we have, the more autonomy we can afford to grant.”
–Henrik Kniberg, Spotify
One of the most widely accepted frameworks for DevOps implementation is the CAMS model, which states that success is based on attention to Culture, Automation, Measurement, and Sharing. Successful ChatOps empowers these: it facilitates collaboration, makes manual work easier, and unifies disparate tools into a central dashboard and team command center, fostering greater access to information. Compared to other tools, ChatOps alone plays a malleable and powerful role that adds value across the entire DevOps lifecycle.