
Trimming Operational Costs: Unveiling Mattermost’s Cross-Cluster Migration
How we managed the cross-cluster migration of our cloud infrastructure, reduced operating costs by 40%, and what to know before migrating your Mattermost workspace.
When it comes to managing infrastructure resources, striking a balance between rightsizing and cost optimization is crucial. Our cloud infrastructure at Mattermost runs on multiple Kubernetes clusters, RDS clusters, and S3 buckets, all isolated from each other for enhanced security and performance. However, this isolation posed challenges in migrating workspaces across different clusters, a requirement that often arises when customers upgrade from our Professional plan to the Enterprise plan, or for consolidation and housekeeping purposes.
The Complexities of Cross-Cluster Migration
The task of migrating workspaces encompasses various components, including:
- Transitioning a workspace database from one AWS RDS cluster to another (utilizing
pg_dumpandpg_restore) - Migrating storage of files between AWS S3 buckets
- Copying the Mattermost custom resource
- Updating our internal database/orchestrator
- Switching DNS records in Cloudflare
- Transferring various Kubernetes components
- Updating customer database configurations
Our Comprehensive Migration Plan
Embarking on this migration journey required a well-thought-out plan to ensure a seamless transition with minimal disruption. Below is a step-by-step breakdown of our designed migration plan:
- Hibernate the Workspace: To ensure data consistency, it’s crucial to prevent any new data from being generated during the migration process. By hibernating the workspace, we halt any data write operations, thus averting any discrepancies post-cutover.
- Customer Redirection: We redirect customers to a maintenance webpage on their web portal. This measure not only fosters a smoother migration process but also enhances transparency, keeping customers informed during the migration phase.
- Lock the Workspace: Locking the workspace prevents interruptions from internal processes. For instance, this step ensures that operations like waking up or updating the workspace are temporarily disabled, paving the way for an undisturbed migration.
- Initiate Database Dump: Kickstart the
pg_dumpprocess using the commandpg_dump -v -d ${DATABASE_URI} -Fc --file=${DUMP_FILE}. This command facilitates a database dump in custom format, which later allows for various options withpg_restore, such as job parallelization. - Target Database Identification: Locate a logical database/schema within the target RDS cluster, where
pg_restorewill place the dumped database, setting the stage for the restoration phase. - Namespace Creation: Establish a new namespace in the target Kubernetes cluster. This namespace will house all the Kubernetes resources transferred from the source cluster.
- S3 Object Sync: Synchronize S3 objects between the source and target buckets to maintain data integrity, as these exist in separate buckets due to our isolation strategy.
- Transfer Kubernetes Resources: Retrieve Kubernetes components/resources as YAML from the source cluster and apply them to the target cluster, ensuring a mirrored environment for a seamless transition.
- Update Mattermost Custom Resource: Modify the Mattermost custom resource to reflect the new database credentials, S3 buckets, etc., and apply it to the new cluster, aligning the configurations with the new environment.
- Schema Creation: In the identified target logical database from step 5, establish a new schema with identical username, password, and relevant permissions, paving the way for database restoration.
- Execute Database Restoration: Run the
pg_restorecommand:pg_restore -v --jobs=2 -d ${DATABASE_URI} ${DUMP_FILE}. This command restores the dumped database in the target RDS cluster, utilizing 2 jobs parallelization for efficiency. - Update Configurations Table: Execute an SQL command to refresh the configurations table of the Mattermost workspace, reflecting the updated target PostgreSQL URI.
- Notify Internal Database Orchestrator: Inform the internal database orchestrator about the workspace changes concerning its updated logical database/schema and its new target Kubernetes cluster.
- Unlock the Workspace: Unlock the workspace, reinstating the ability to wake up or update the workspace.
- Revert Maintenance State: Remove the workspace from the maintenance state, enabling the re-activation of the resource.
- Wake Up the Workspace: Wake up the workspace, signaling the completion of the migration process.
- DNS Record Update: Our internal orchestrator then verifies the migrated workspace in the new target cluster and updates its DNS record in Cloudflare to reflect the new location/ingress in our target Kubernetes cluster.
Each step of this comprehensive plan was executed with precision, ensuring a smooth cross-cluster migration, and setting a strong precedent for future infrastructure optimization projects.
Overcoming Hurdles
Downtime
Challenge: The migration operation necessitates downtime as the workspace needs to be hibernated.
Solution: To minimize customer disruption, we conducted operations during off-working hours and within maintenance windows. Initially, our process required up to two hours of downtime. However, by refining our approach and leveraging automation, we significantly reduced the impact on our customers. By the second migration, we had decreased the necessary downtime to a mere 15 minutes—1/8th of our original process time!— ensuring that customer disruption was kept to an absolute minimum.
Large Data Volumes in S3
Challenge: Syncing customer data, which can range from multiple gigabytes to terabytes, posed a significant time challenge, with operations taking almost a minute per gigabyte of data transferred. This made the sync operation time-consuming and could potentially lead to extended downtime during migration.
Solution: By initiating the S3 sync operation ahead of the migration, we tackled this issue head-on. Our proactive approach allowed us to transfer the bulk of the data offline, significantly reducing the sync time during the actual migration cutover to almost negligible amounts. This pre-migration synchronization demonstrates our commitment to minimizing downtime and customer impact.
Large Databases
Challenge: Many customers have large databases.
Solution: Employ parallel jobs for pg_restore and utilize a custom file type for pg_dump. Simultaneously, increase the CPU resources of the target RDS cluster, as pg_restore can be resource-intensive.
This endeavor not only taught us the importance of meticulous planning and execution but also paved the way for future projects aiming at optimizing our cloud infrastructure. Through a blend of careful strategizing and technical finesse, we’ve made significant strides in ensuring a more efficient and cost-effective infrastructure, reaffirming our commitment to delivering exceptional service with optimized operational efficiency.
Concluding Remarks on Cross-Cluster Migration
The process of migrating workspaces across clusters has provided us with a clearer understanding of our infrastructure’s capabilities and areas for improvement. The primary goal was to reduce operational costs, and the successful completion of these cross-cluster migrations has moved us a step closer to that objective. Through careful planning and execution, we managed to mitigate the challenges that came our way, ensuring a smooth transition with minimal disruption to our customers.
The graph below illustrates the cost reduction journey, with our strategic initiatives resulting in a consistent decrease in operational costs month over month, approximately a 40% reduction.
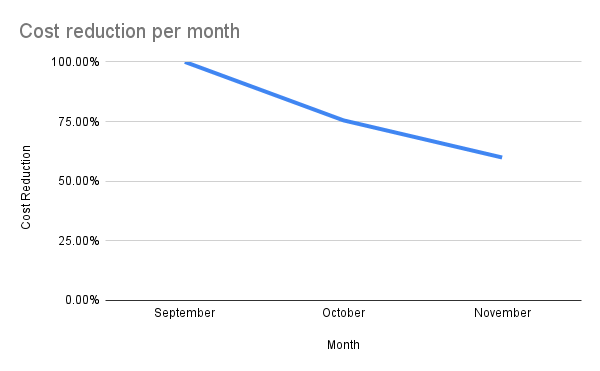
The reduction in operational costs and the streamlining of our infrastructure setup are modest yet significant steps toward achieving a more efficient and cost-effective operational framework. The experience has also furnished us with insights that will be valuable in planning future infrastructure optimization projects.
We look forward to identifying more opportunities for enhancing efficiency and reducing costs in our cloud infrastructure. Our journey so far has been instructive, and we are optimistic about applying the learnings from these projects in our ongoing and future infrastructure optimization efforts.
To read more articles and tutorials about running and deploying the Mattermost platform from the Mattermost R&D team, be sure to check out the Deployment Engineering Knowledgebase in the Mattermost Handbook.




