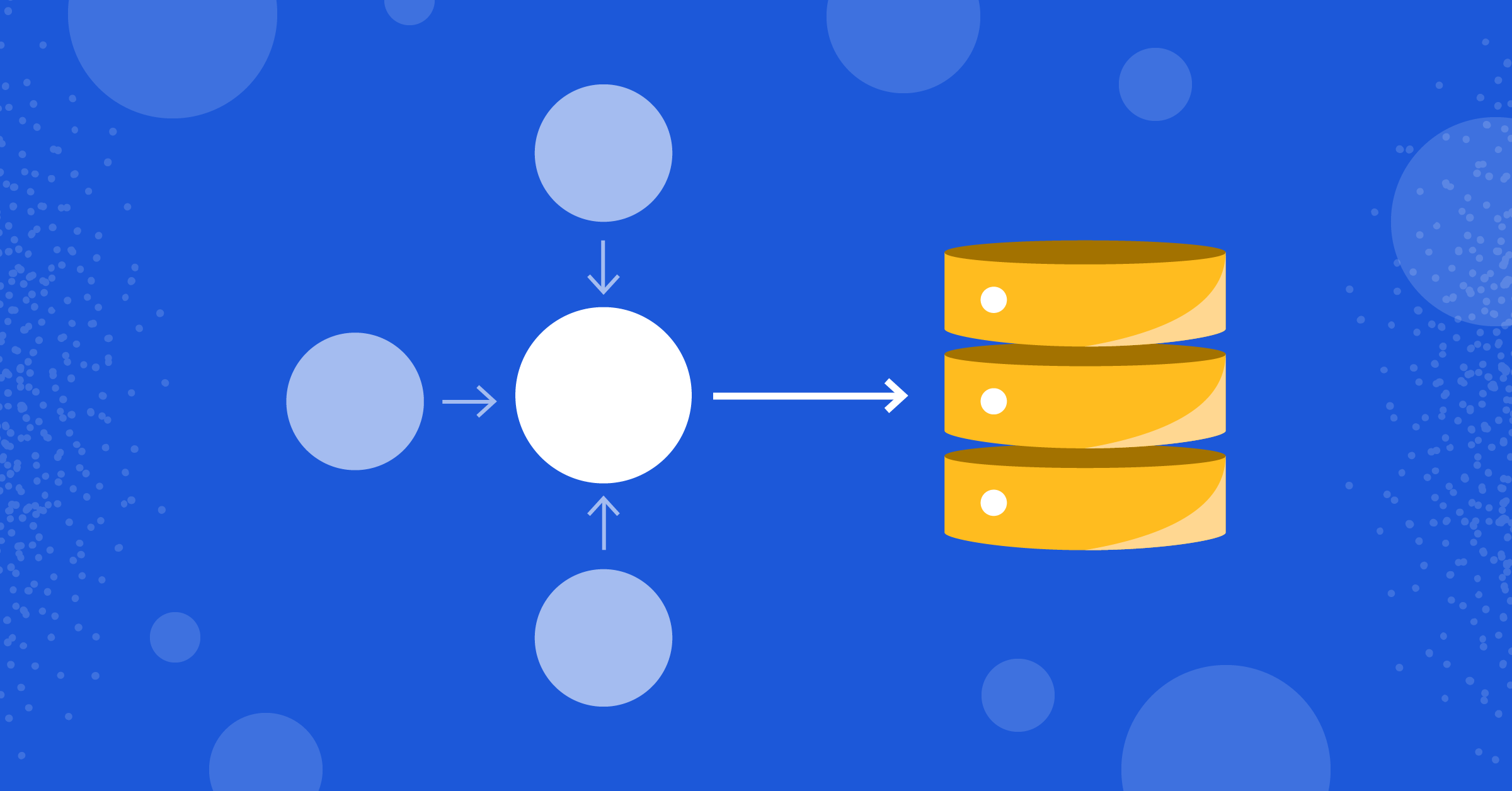
How We Use RPC to Share Database Connections and Scale our Multi-Product Architecture
The database/sql package in the Go standard library maintains a pool of connections so that all queries going through a single *sql.DB instance will reuse the same pool. This is great because you get a connection pool out of the box. But what if you need to share the same connection pool across processes? How do you use the same API in different processes but still reuse the same pool?
Background: Mattermost’s Plugin Architecture
Mattermost has a plugin architecture to extend its functionality to a user’s workflow. These plugins are separate processes running independently from the main Mattermost server. And they typically communicate with the server via an RPC API.
This has served us well for several years, but as plugins started to be more powerful, they needed to maintain their own state in separate database tables. Initially, we just had a single table offering key-value semantics for all plugins via the plugin API, but clearly that wasn’t enough. Plugins needed access to the database.
This created a new challenge. Since each plugin was its own isolated process, each of them would open additional connections to the DB. And the more plugins we had, the more amplified this would become. Our users started to complain that the system exceeded the max_connections config setting on their DB.
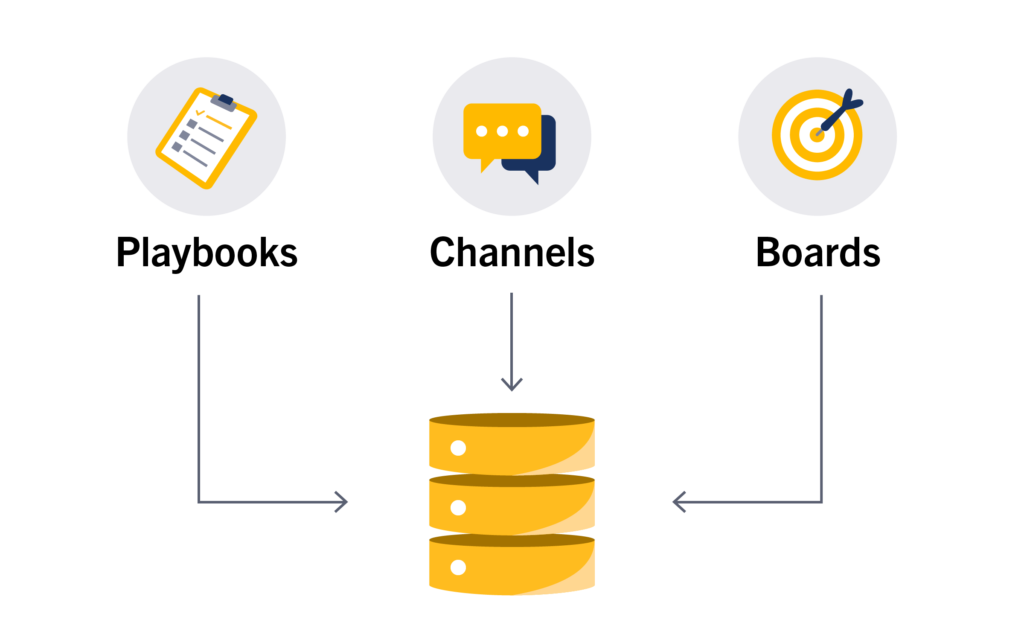
What we needed was to route all queries via the server so that a single connection pool would be used by all plugins. An obvious solution here is to put a connection proxy (like PgBouncer or ProxySQL) in front of the database to multiplex between connections. While that works (and indeed we use that in our Cloud environments), ours is primarily an on-prem software, which means we just cannot ask all of our customers to add a DB proxy in their stack.
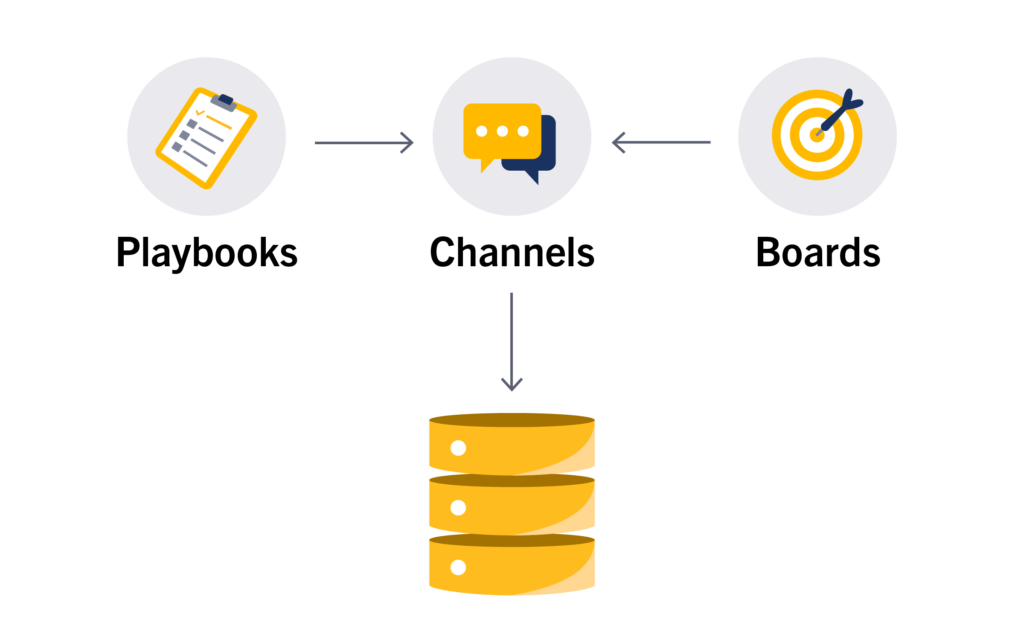
Approaches to Sharing Database Connections
1. Implement RPC APIs for the queries
The most straightforward solution would be to have RPC APIs for these DB calls and have the plugins make the RPC calls to the server, instead of using the DB directly.
However, all of the queries contained logic that was relevant to the plugin, not the server. So it would not make sense to place that code in the server. And moreover, even if we did have a way to do that, writing API wrappers for every new DB call wasn’t going to scale. SQL queries change very often and it would be a nightmare to maintain the RPC API. We needed something low-level.
2. DB API on top of RPC
A better alternative was to use a database query API, and have the API marshal the query params via RPC and execute them on the server. This was a generic solution and did not require you to write new APIs for every new query.
However, we have different teams working on different plugins. A new query API would mean all of the existing code would need to be migrated to the new API, which a lot of teams were reluctant to do.
What we needed was for the existing code to work without any change, but at the same time route the queries via RPC to the server instead of hitting the DB.
3. database/sql/driver
The database/sql package is just a set of methods that run the database/sql/driver interface. This driver interface is actually the one that communicates with the DB. Therefore, if we could implement our own driver interface that just routed all queries, then we could solve this problem with practically no change at all!
All that would be needed was to change
db, err := sql.Open(driverName, dataSourceName)to
db := sql.OpenDB(driver.NewConnector(...))Implementing the database/sql API on top of RPC
We decided that option #3 looked to be the most promising of our solutions, and went to work.

The overall idea was pretty simple: at the client side, we create implementations of driver.Connector, driver.Conn, and others. These implementations would communicate via an RPC API to the server.
// Compile-time check to ensure Connector implements the interface.
_ driver.Connector = &Connector{}
// NewConnector returns a DB connector that can be used to return a sql.DB object.
// It takes a plugin.Driver implementation.
func NewConnector(api plugin.Driver) *Connector {
return &Connector{api: api}
}The way it would work is to assign ids to each object (connection, statement, transaction, rows) in the database/sql universe on the client side, and track those objects in a map on the server.
Here is a brief snippet of the plugin.Driver interface:
type Driver interface {
Conn(isMaster bool) (string, error)
ConnPing(connID string) error
ConnClose(connID string) error
ConnQuery(connID, q string, args []driver.NamedValue) (string, error)
ConnExec(connID, q string, args []driver.NamedValue) (ResultContainer, error)
...
}So a *Conn.Ping method on the client would call the ConnPing API and pass the connection ID. On the server side, it looked something like this:
type DriverImpl struct {
s *Server
connMut sync.RWMutex
connMap map[string]*sql.Conn
txMut sync.Mutex
txMap map[string]driver.Tx
stMut sync.RWMutex
stMap map[string]driver.Stmt
rowsMut sync.RWMutex
rowsMap map[string]driver.Rows
}
func (d *DriverImpl) ConnPing(connID string) error {
d.connMut.RLock()
conn, ok := d.connMap[connID]
d.connMut.RUnlock()
if !ok {
return driver.ErrBadConn
}
// Now use the conn to make the ping and return appropriately.
}Roadblocks
1. Raw access to driver.Conn
The first problem we hit was to get access to the raw driver.Conn instance. Since the client was working at the database/sql/driver level, once we would get the query params on the server side, we cannot go via the database/sql layer again! We needed access to the underlying driver.Conn object to directly call the driver APIs.
Fortunately, the *Conn.Raw method was there to save the day!
And so this is how the rest of ConnPing actually looks:
return conn.Raw(func(innerConn interface{}) error {
return innerConn.(driver.Pinger).Ping(context.Background())
})2. Cannot pass context.Context
The second problem was that since context.Context was an interface with an unexported underlying struct, we could not pass that, because on the server side, the Go unmarshaler did not know the underlying implementation of that. So as a result we could not pass information like timeout values and such. While this was solvable, it did not affect us that much because the timeout values were the same for all queries and we just set them on the server side.
3. Errors
An interesting question was on how to relay back errors. Errors like sql.ErrNoRows or sql.ErrConnDone were just error variables and not structs.
So we came up with a cheap method of assigning integer codes to errors and re-mapping them to their respective variables on the client side. Fortunately, there were only a handful of them to consider. And concrete error structs like *mysql.MySQLError and *pq.Error were handled by just registering the types.
gob.Register(&pq.Error{})
gob.Register(&mysql.MySQLError{})
gob.Register(&ErrorString{})On the server side, we would encode errors like this:
func encodableError(err error) error {
if _, ok := err.(*pq.Error); ok {
return err
}
if _, ok := err.(*mysql.MySQLError); ok {
return err
}
ret := &ErrorString{
Err: err.Error(),
}
switch err {
case io.EOF:
ret.Code = 1
case sql.ErrNoRows:
ret.Code = 2
case sql.ErrConnDone:
ret.Code = 3
...
}
return ret
}And back on the client, decode them like this:
func decodableError(err error) error {
if encErr, ok := err.(*ErrorString); ok {
switch encErr.Code {
case 1:
return io.EOF
case 2:
return sql.ErrNoRows
case 3:
return sql.ErrConnDone
...
}
}
return err
}4. Differing driver implementations
We support both MySQL and Postgres as database backends, so our driver implementation needed to support both. But we observed that the actual implementations differed in their coverage of methods implemented. The MySQL driver implemented some methods that the Postgres driver didn’t, and vice-versa. So we had to use a common sub-set of the methods common to both implementations. This wasn’t a major blocker for us since we weren’t particularly using those features. Following is the list of methods we couldn’t use:
RowsColumnTypeLength(rowsID string, index int) (int64, bool)
RowsColumnTypeNullable(rowsID string, index int) (bool, bool)
ResetSession(ctx context.Context) error
IsValid() boolConclusion
That was the last major hurdle we observed during deployment. It has been several months since the system was deployed, and we haven’t observed any more issues with it. The performance overhead has been negligible, since it’s inter-process, and the gob encoding/decoding has been reasonably fast.
Although not perfect, this helped us to solve a real problem in a clean way. The source code for this is available here, and the server implementation is here. Right now, it is deeply tied to our Mattermost libraries. But if you have a use case for this, please do let us know and we would be happy to extract it outside the server. And pull requests to do so would be even more appreciated!If you think there was a better way to do this, please do drop by our community server at https://community.mattermost.com and we would love to hear your thoughts!
—
Written by Agniva De Sarker – @agnivade on community.mattermost.com and @agnivade on GitHub
Join us on community.mattermost.com!




