
Playbooks in Action: An Incident Response User Story
While service incidents can be wildly dissimilar, they tend to have one thing in common: a need for quick resolution. Response teams need a robust, repeatable process to follow that ensures fast, mistake-free execution, especially for those 4 AM calls. Having a documented checklist saved where the entire team can access and use it at any time could make the difference between quick resolution or compounding the problem.
Mattermost Playbooks codify effective, repeatable resolution processes so that any on-call engineer can be successful. But what does that look like in practice?
Incident Response Scenario: Acme Co.
Here’s an example user story for using Mattermost to respond to a service outage that ties together the process, people, and third-party tools necessary for resolution. Our internal teams use stories like this to build out the platform with realistic use cases in mind. “Acme Co.” is a fictional entity:
Tools Acme Co. Uses
- PagerDuty – Maintaining on-call schedules and sending SMS messages to engineers.
- DataDog – Aggregating data from all web services in one place.
- Moogsoft – Intelligent alerting to reduce alert noise and escalate outages appropriately.
- CircleCI – Build consumer-facing apps and back-end server stack.
- GitHub – Code repository and deployment orchestration.
- AWS – Web service hosting.
- Jira – Sprint planning and issue management.
Acme Co. implemented Mattermost to reduce engineering context switching between the wide selection of tools in their software development stack, particularly when responding to service incidents. They chose Mattermost because it enables their SREs to respond to incidents entirely within Mattermost and avoid creating excessive noise for affected teams.
Now that the scene is set, let’s dive into Acme Co.’s incident response workflow!
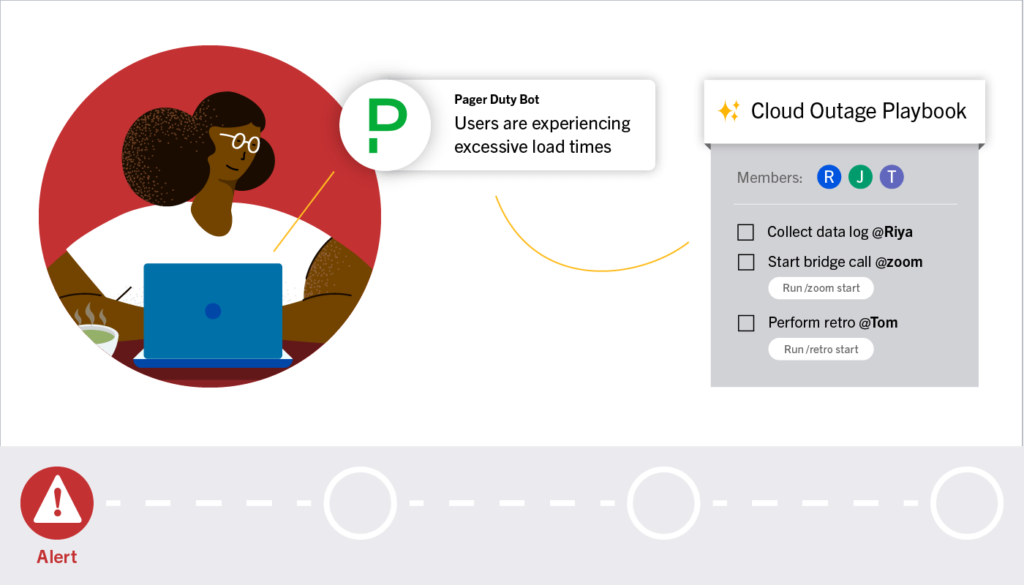
Alert
Current Time: 4:12 AM ET
It was a dark and stormy night. Shortly after 4 AM ET, Moogsoft begins reporting degraded performance in the app server scaling services as European demand hits its daily peak. 10% of users begin to experience excessive load times and unspecified errors while carrying out normal app functionality, crossing the threshold for a minor incident.
PagerDuty sends an alert to the on-call SRE, and a webhook is triggered to kick off the incident response Playbook in Mattermost.
Mattermost Experience
Channels
- The preconfigured Playbook automatically creates a Mattermost channel for the incident and adds the on-call SRE, their manager, and the backup on-call SRE to the channel.
- The on-call SRE receives an automated message in Mattermost that provides instructions on how to proceed and what they need to do to escalate the issue. This information is automatically added to the Playbook retrospective.
Playbooks
- A Playbook is deployed by the original PagerDuty alert that lists out the response workflows that the on-call SRE is expected to perform. The checklist is displayed alongside the incident channel, and includes links to key resources, participants, and the owner of the run (the on-call SRE who has been automatically assigned as incident commander).
- Automated messages are posted to the incident’s Channel, which provides additional instructions at each step of the Playbook. Without leaving the Channel, the on-call engineer is able to trigger and monitor:
- A CircleCI build process that stages a roll-back of all code changes made in the last 24 hours for instant deployment. The logs from CircleCI can be requested with a slash command in the channel, including a slash command to deploy the build. This is a precautionary step to save time later if required and no action is taken at this time.
- An AWS reset process that refreshes all app, database, proxy services, and load-balancing services. Vital log data from DataDog is embedded into an interactive post in the incident Channel and any alerts from Moogsoft are published as individual posts in the channel. All significant updates are also added to the relevant boards.
Boards
- The on-call SRE creates a new board, following instructions in a Playbook task, connects it to the new incident response channel, and populates it with the following informational cards:
- Moogsoft report – A detailed analysis of the outage with data imported from Moogsoft.
- Support contacts – Contact information for the on-call SREs.
- Resolution Status – Provides high-level detail about the current measured outage level reported via DataDog, the trending direction (improving, stagnant, degrading), and a series of comments that indicate the current percentage of degraded experiences. New comments are added whenever there are changes.
- Recent PRs – A list of all PRs from the last 48 hours that were merged into the affected GitHub repo.
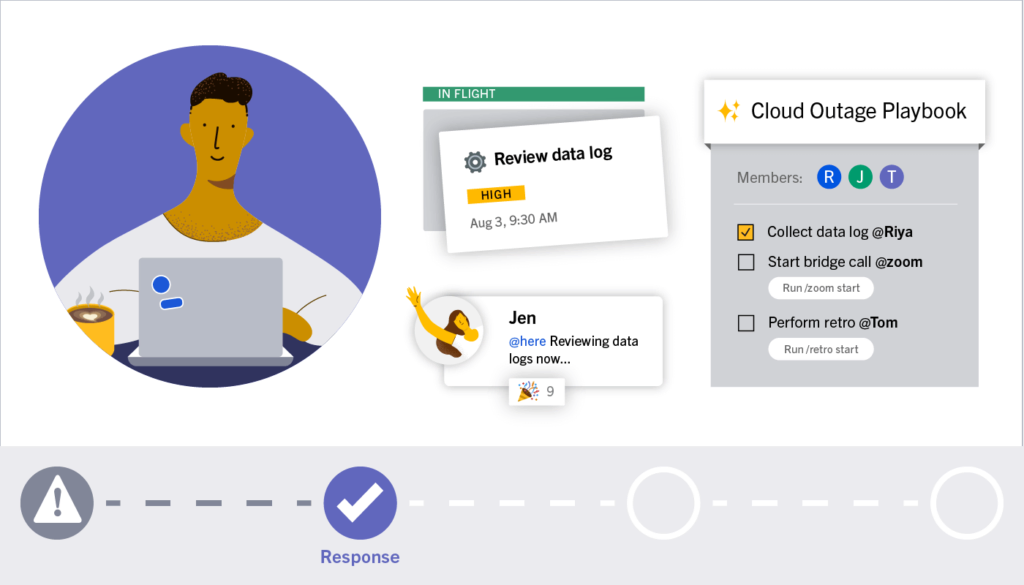
Response
Current Time: 4:19 AM ET
- The AWS refresh causes an increase in connection errors at the load-balancer that handles app to database connections. The number of users having degraded experiences surges to 25%, triggering the threshold for an on-call escalation to the secondary SRE. The outage begins to affect some of the company’s largest customers.
- The secondary on-call joins the effort and the two SREs deploy a temporary response plan that reduces the degradation rate below 10%.
- The secondary on-call engineer is able to get up to speed quickly by reading the channel backlog and viewing the Playbook timeline to date. They may also observe any Boards cards in progress and completed to see what has been done so far and avoid duplicating work and conversations.
Mattermost Experience
Channels
- Automated messages for the completion of tasks keep the two SREs aligned and aware of the progress the other is making.
- The engineers responsible for maintaining load-balancing and database services are added to the incident channel and each receives a message that summarizes the outage and the current resolution status.
- The account managers who oversee the accounts of the affected customers are added to the channel and receive an automated message that summarizes the impact the outage is having on affected customers.
- Additional stakeholders may join the open response channel to observe progress and status updates.
Boards
- Additional cards are created within Boards to document log information and status updates for the load-balancing and database services. The SREs are reminded to post updates here by the Playbook.
- The team creates a card for each of the large customers that are affected by the outage with contact information and a linked real-time chart shows the current impact of the outage.
Playbooks
- An escalated workflow is created by an automation in the incident playbook, and the tasks are assigned amongst the two on-call SREs. Through a mixture of Playbooks and Channels interactions, they are able to completely redeploy the load-balancing, database, and app services into two alternative data centers to triple the number of servers dedicated to serving the EU market.
- Additional ad hoc tasks can be added and assigned within the playbook as the situation develops.
- The incident commander posts a status update to the playbook that is logged in the incident report and is also immediately broadcast to multiple channels and stakeholders that are following the situation.
- Each response task is documented in the playbook retrospective with detailed information about the impact on the outage.
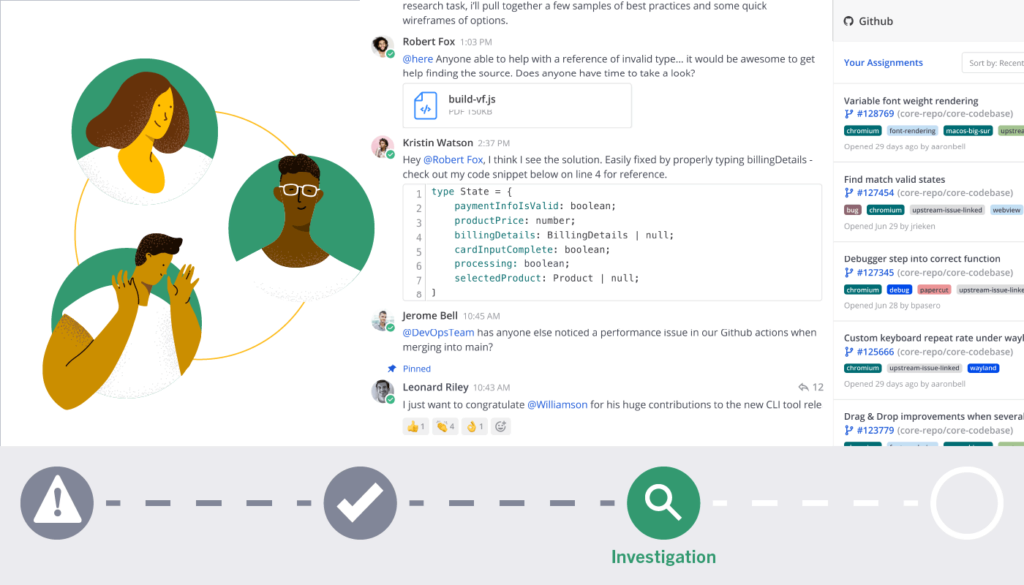
Investigation
Current Time: 4:34 AM ET
Once the app degradation rate drops below 10%, the SREs are prompted (by monitoring tools that send system status updates into the channel as webhooks) to begin investigating code changes in the last 24 hours to look for something that might have triggered the outage. One by one, Mattermost prompts the SREs to review all merged PRs and displays the code diff and build log in an interactive message for each commit.
One SRE finds a PR that references deprecated infrastructure for issuing certificates to make an encrypted connection through the load-balancer to the database server. Using the interactive message, the SRE is able to trigger a merge rollback for the related commits and a new build is initiated for this version. All build logs are automatically displayed in the Channel.
The Mattermost Experience
Channels
- SREs add related messages from various channels to the Playbook timeline to provide discussion history, diffs, and information from each of the code reviews. The SREs review all code changes line-by-line and are able to initiate a commit rollback using an interactive message.
- Once the rollback takes place, interactive messages embed real-time build logs from CircleCI for the SRE to monitor.
Playbooks
- Playbook tasks prompt the SREs to continue expanding the rollout of the fixed deployment when success criteria are met. The SREs are able to move the entire userbase to the fixed version without leaving Mattermost.
- The SRE saves the post that indicated app degradation rate dropped below 10% to the incident timeline so that it is timestamped and can be referenced later during the retrospective.
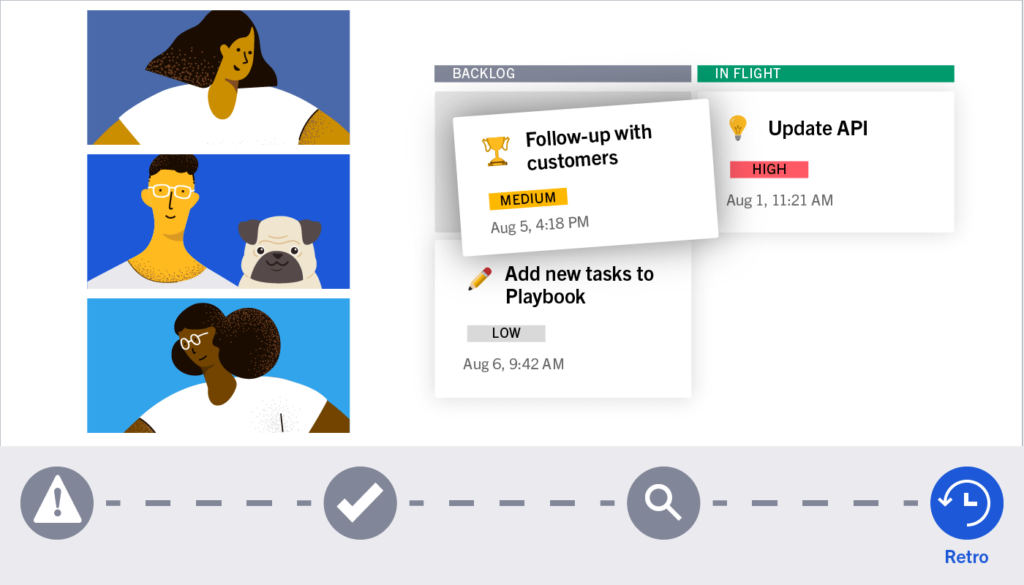
Retrospective
Current Time: 5:07 AM ET
- All users have now been successfully migrated to the rolled-back deployment, and Moogsoft is reporting everything as 100% functional. The SREs post a status update that the incident is resolved, which is automatically broadcast to multiple channels for visibility that the incident is resolved, add their final comments to the built-in retrospective report by referencing the incident timeline within Mattermost, and go back to their personal morning routines.
- A retrospective meeting is scheduled for later that week and all members of the incident channel are invited. The first employees connect to Mattermost starting around 8:30AM on Friday and within minutes are able to get completely caught up on the outage by reviewing the channel history, Playbooks timeline, and the incident board. Everyone is prepared to plan process improvements during the retrospective meeting. Once relevant code has been identified as the culprit for the outage, the engineers who maintain that code are added to the contacts card in Boards and invited to the retro. This data is pulled from PagerDuty and GitHub.
- A Zoom integration alerts all participants that the retrospective meeting has started. During the meeting, the team creates a list of tasks within Boards to create improvements that will prevent this type of issue from happening in the future. At the end of the meeting, these tasks are exported into Jira and assigned owners for sprint planning.
Key Features in This Story
- Real-time, interactive log and status information embedded in Mattermost Channels, Playbooks, and Boards.
- Mirrored content between Channels, Playbooks, and Boards.
- Automatic triggers to add engineers to incident channels who maintain services affected by a related outage and create cards to document outages.
- Code, ticket, and build management system integrations notify of comments, review requests, updates and more in channels and plugin dashboards.
- Playbook retrospective that tracks all of the events in the correct chronological order as well as publishing a summary report to stakeholders.




